- GPUs offer massive parallel processing capabilities along with associated buses and memory sub-systems.
- GPUs usage have an established programming model and a mature developer ecosystem.
- GPUs are highly modular and scalable for varying power and performance requirements.
- GPUs are well-integrated into established platforms (motherboards and PCI Express buses), enabling rapid adaptation in system-level designs.
The GPU has a long history as a co-processor to the primary CPU in PCs. Designed to handle tasks too complex or time-consuming for the CPU, it was originally developed to rapidly process images on screens and remains crucial for high-performance computing. Its primary function is to accurately color each visible pixel, enhancing the lifelike quality of visuals. GPUs excel at processing large numbers of pixels in parallel, each with different data but similar data structures and instructions. They are also vital for delivering real-time responses in interactive experiences like gaming and movies, ensuring smooth, flicker-free rendering. In summary, the GPU’s key roles are to process extensive data per pixel, manage many pixels in parallel, consume low power, and provide high performance.
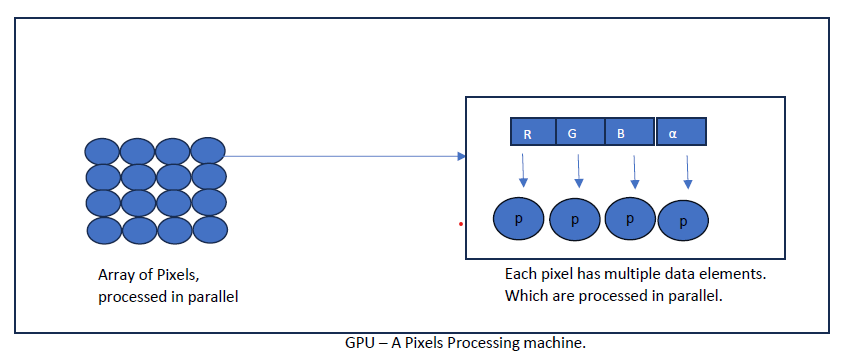
These foundational characteristics of processing repetitive structures of pixels in parallel are somewhat analogous to the parallel processing of neurons. Because of this similarity, GPUs are being explored and used for AI processing. Let's understand the unique parallel processing capabilities of GPUs in little more details.
The parallel processing architectures of ALUs include several variants: SIMD (Single Instruction Multiple Data), SIMT (Single Instruction Multiple Threads), and SMT (Simultaneous Multithreading).
- SIMD (Single Instruction Multiple Data): This architecture executes the same instruction on multiple data elements simultaneously. It is optimized for processing data arrays (matrices) efficiently through vector processing, which is crucial for rapid matrix multiplications in AI algorithms and data models.
- SIMT (Single Instruction Multiple Threads): SIMT operates similarly to SIMD but allows the same instructions to process data across multiple parallel threads. Threads are individual execution units created by higher-level applications for hardware. SIMT enhances workload creation and execution with optimal speed and power efficiency.
- SMT (Simultaneous Multithreading):SMT represents an evolution where multiple threads are executed concurrently within the same ALU engine, improving resource utilization and overall processing efficiency.
Beyond its parallel processing capabilities, the GPU is scaled to manage the large volumes of data
needed by these engines. As parallel processing increases, other machine elements must also scale
accordingly. The infrastructure supporting processing engines is designed to move data efficiently
with minimal energy consumption while ensuring continuous engine utilization. Timely data
availability is crucial for optimizing machine use, similar to how an idle factory engine waiting for
materials is inefficient.
GPUs, with their deployment of massive parallel processing engines, incorporate built-in
infrastructure designed to efficiently manage data. GPUs supports characteristics such as reducing
latencies, optimizing cache utilization, and ensuring smooth traffic flow and data integrity suitable
for SIMD/SIMT architectures.
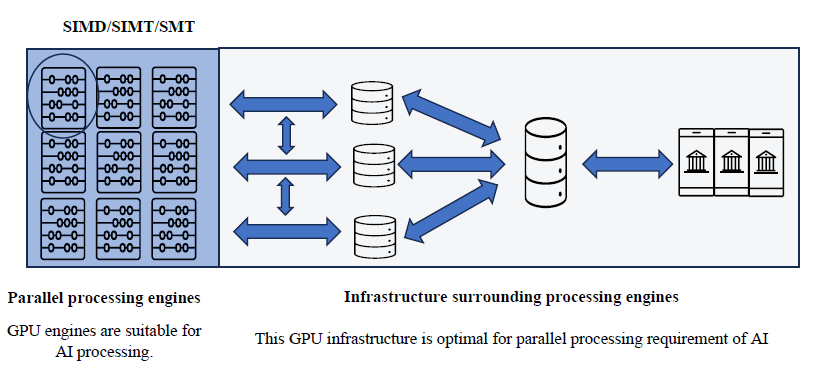
These parallel processing architectures in GPU, demonstrate optimal performance for current AI algorithms and data structures. As AI algorithms continue to advance, GPU architecture is well-positioned to evolve in tandem with these developments. In the next blog, we will go through additional GPU characteristics and their value propositions for AI processing.


