
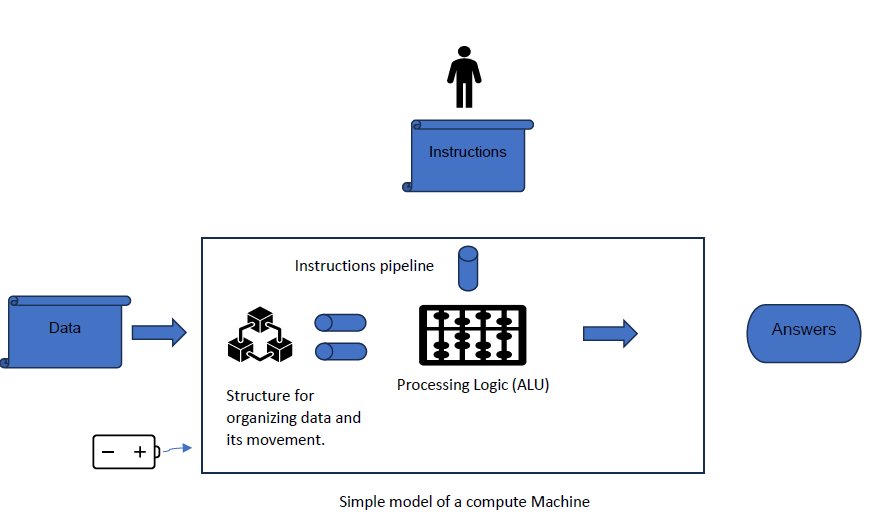
Current Compute Machines & their limitations:
When I refer to a "compute machine," I'm talking about a specific hardware structure made up of digital building blocks. This includes a logic processing engine (ALUs), an assembly pipeline for managing data flow to and from these engines, algorithms for fetching instructions and data,memory, cache organization, extensive data movement networks (Network on Chip), power units, and more. The choice of the optimal machine architecture depends on the size and type of data payloads and instructions that need to be processed.
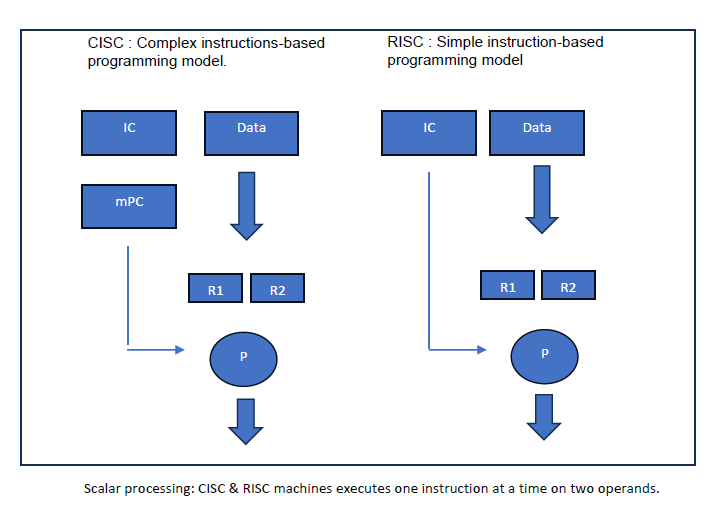
Last four decades are dominated by CISC and RISC architecture-based compute machines.
Don't hesitate
Take your career and expertise to the
next level!
We are vlsideepdive, we offer a diverse range of educational resources and engaging experiences to help you master VLSI (Very-Large-Scale Integration), Embedded and Semiconductors concepts.

Created with
